Jimmy Dunn
UC Berkeley MIDS Graduate
CareerCoach
UC Berkeley MIDS Applied Machine Learning Class Project
Special thanks to Sonali Serro for being a fantastic group partner!
Data Science for Good Kaggle Competition
Context
The U.S. has almost 500 students for every guidance counselor. Underserved youth lack the network to find their career role models, making CareerVillage.org the only option for millions of young people in America and around the globe with nowhere else to turn.
To date, 25,000 volunteers have created profiles and opted in to receive emails when a career question is a good fit for them. To help students get the advice they need, the team at CareerVillage.org needs to be able to send the right questions to the right volunteers. The notifications sent to volunteers seem to have the greatest impact on how many questions are answered.
Objective
Our objective was to develop a recommendation system using unsupervised and semi-supervised learning methods to recommend new student questions to the professionals who are most likely to answer them.
By using stemming and tokenization on the question corpus, we were able to develop a similarity-based recommendation system that scored a mean average precision of around 65%. We believe this system, in combination with a similarity system that directs new question askers to similar questions that have already been answered, CareerVillage could increase their new question 24 hour answer rate to 95%.
Approach
Step 1: When a student asks a new question, are there similar questions and answers pairs in CareerVillage that are relevant?
Step 2: Identify the professionals who answered those questions, and subsequently use mean average precision to evaluate and recommend the professionals who are most likely to answer the question.
Data
CareerVillage.org has provided several years of anonymized data and each file comes from a table in their database. The data comes in 15 separate csv files, the largest of which has 1.85 million rows, and take up a total of 67MB.
# Additional libraries for install, if needed.
# ! pip install wordcloud pyldavis nltk
# Project modules.
from code import etl, similarity, recommender, evaluator
# Plotting and display.
import pandas as pd
import matplotlib.pyplot as plt
import pyLDAvis.sklearn
# SK-learn libraries for dimensionality reduction, and visualization
from sklearn.decomposition import TruncatedSVD
from sklearn.manifold import TSNE
from IPython.display import HTML
# WordCloud library.
from wordcloud import WordCloud
# Ignoring warnings related to pyLDAvis
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
Load the data
We’ve developed an etl.py module to handle reading in questions and answers data from csv files as pd.DataFrame objects and perform data type enforcements by column for the following attributes: [('answers_body', str), ('questions_body', str), ('questions_title', str), ('answers_date_added', pd.DateTime), ('questions_date_added', pd.DateTime)]. We then strip the HTML tags embedded in the questions and answers text data.
# Load all csv files, clean and return as individual dataframes.
data = etl.fetch_and_clean_data()
Some interesting statistics
print('There are')
print(f'\t{len(data.students):,} Students')
print(f'\t{len(data.professionals):,} Professionals')
print(f'\t{len(data.questions):,} Questions')
print(f'\t{len(data.answers):,} Answers')
print(f'\t{len(data.comments):,} Comments')
print(f'\t{len(data.tags):,} Tags')
print(f'\t{len(data.emails):,} Emails sent')
There are
30,971 Students
28,152 Professionals
23,931 Questions
51,123 Answers
14,966 Comments
16,269 Tags
1,850,101 Emails sent
# Merge Tags and Questions.
tags_questions = data.tags.merge(data.tag_questions, how='inner', left_on='tags_tag_id', right_on='tag_questions_tag_id')
# Calculate # of Professionals and Students who follow Tags.
users_tags = list(data.tag_users['tag_users_user_id'].unique())
professionals_tags = len(data.professionals[data.professionals['professionals_id'].isin(users_tags)])
students_tags = len(data.students[data.students['students_id'].isin(users_tags)])
print(f'\t{(data.answers["answers_question_id"].nunique()/len(data.questions))*100:.0f}% Questions have at least 1 Answer')
print(f'\t{len(tags_questions.groupby("tag_questions_question_id").nunique())/len(data.questions)*100:.0f}% Questions have at least 1 Tag')
print(f'\t{(professionals_tags / len(data.professionals))*100:.0f}% Professionals follow Tags')
print(f'\t{(students_tags / len(data.students))*100:.0f}% Students follow Tags')
print(f'\t{((len(data.professionals) - data.answers["answers_author_id"].nunique())/len(data.professionals))*100:.0f}% Professionals have answered Zero Questions!')
97% Questions have at least 1 Answer
97% Questions have at least 1 Tag
91% Professionals follow Tags
15% Students follow Tags
64% Professionals have answered Zero Questions!
Questions-Tags WordCloud
tag_cloud = WordCloud(collocations=False, width=1440, height=1080).generate(' '.join(tags_questions['tags_tag_name']))
plt.figure(figsize=(12, 12))
plt.title('Questions-Tags WordCloud')
plt.imshow(tag_cloud)
plt.axis('off')
(-0.5, 1439.5, 1079.5, -0.5)

Similarity Approach - LSA
LSA or Latent Semantic Analysis takes a term-document matrix as input and performs Singular Value Decomposition (SVD) on the matrix. Intuitively you can think of this as a way to only keep the most significant dimensions in our transformed space, thus discovering latent patterns in the data.
With the resulting feature vector, we were able to evaluate document similarity using the following approaches,
-
Cosine similarity, to generate a cosine similarity matrix, as well find the top n documents with the highest similarity scores
-
NearestNeighbors, which is the unsupervised learner for implementing neighbor searches. Here again we used the cosine distance metric
-
K-Means Clustering to cluster the documents by their (latent) topics
Please be patient while we load the entire LSA and LDA pipeline transformed questions corpus.
# Initialize the Similarity module, which sets up the LSA and LDA pipelines.
sim = similarity.QuestionSimilarity(data.questions, verbose=True)
Number of documents in questions corpus: 23931
Fitting and Transforming text corpus through LSA Pipeline..
Number of dimensions after vectorization: 13527
Done in: 84.34s
Number of dimensions after SVD dimensionality reduction: 2000
Explained variance of the SVD step: 73%
Fitting and Transforming text corpus through LDA Pipeline..
Number of dimensions after vectorization: 6133
Done in: 85.81s
Number of LDA Topics: 30
Finding the Words that Matter: tf-idf
The first step is to convert the collection of raw text documents to a matrix of TF-IDF features. The following are some of the hyperparameters that we used,
max_df: 0.8 This is the maximum frequency within the documents a given feature can have to be used in the tf-idf matrix. If the term is in greater than 80% of the questions or answers it probably has little meanining.
min_df: 0.002 Given that the typical questions in CareerVillage are sometimes less than 50 terms, we do want a fairly low value for this hyperparameter.
ngram_range: (1, 2) This means we’ll include unigrams, and bigrams.
preprocessor: We perform important text preprocessing like removing numbers and special characters, punctuations, coverting to lower case, and stripping any excess white space(s).
tokenizer: We use the NLTK’s PorterStemmer which reduces each word to its root using Porter’s stemming algorithm. We exclude our stop_words from the tokenization, because the stop_word removal occurs after the tokenization step.
stop_words: We create a custom stop_words list from the Tfidf English stop words, nltk English stop words, and corpus stop words! The last set of stop words were identified during the exploration phase that are very commonly present in a career-related text, and don’t convey much meaning during the learning. Some examples, school, college, career, jobs, years, advice, help etc.
Working in High-Dimensional Space: Dimensionality Reduction
There are many methods to reduce the dimensionality of a term-document matrix. A very common method is to apply singular-value decomposition (SVD) to a tf-idf weighted term-document matrix. This procedure is often called latent semantic analysis (LSA). After transforming two texts with LSA, the cosine distance between them is a good measure of their relatedness.
The intuition behind this idea is that we expect certain words like “enjoy,” “happy,” and “delight” to have similar meanings. Instead of including a column for each word separately, we compress them into a column that measures the broader idea of enjoyment.
The most important hyperparameter in this step is the n_components. We decided to use 2000 components.
K-Means Clustering and Visualization using t-SNE
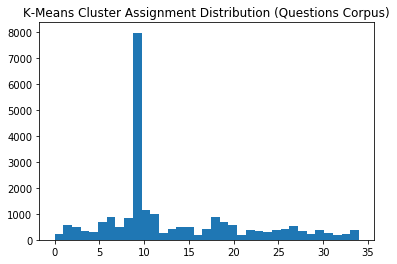
With K-Means Clustering, we can better understand the hidden structure within the data. Once again, choosing the number of clusters was a bit of an art. We tried the “Elbow Method” to find a “good” number of clusters, but with no clear indication. We decided to go with 35 clusters, even though the cluster distribution was not very uniform.
Below is a t-SNE visualization of the K-Means Clusters over the entire questions corpus. t-SNE essentially minimizes a cost function with gradient descent to find a low dimensional data representation that keeps “close” points together in the new dimensions, allowing us to visualize this extremely high original dimensional space.
# Get the results of running K-Means Clustering.
n_clusters, cluster_labels, cluster_centers = sim.get_km_clustering_labels_and_centroids()
Running K-Means Clustering (n_clusters=35) on the LSA transformed text corpus..
Done in: 11.84s
For high-dimensional sparse data it is helpful to first reduce the dimensions to 50 dimensions with TruncatedSVD and then perform t-SNE. This will usually improve the visualization.
# Get the LSA transformed text corpus.
questions_corpus_lsa = sim.get_text_corpus_lsa()
# Perform dimensionality reduction to 50 dimensions.
lsa_reduced = TruncatedSVD(n_components=50, random_state=0).fit_transform(questions_corpus_lsa)
Next, we’ll find a 2-D representation of our 50-dimensional data using t-SNE. This may take a few minutes.
tfs_embedded = TSNE(n_components=2, perplexity=40, verbose=0).fit_transform(lsa_reduced)
Now we can plot the questions features colored according to their k-means cluster assignment.
fig = plt.figure(figsize = (10, 10))
ax = plt.axes()
plt.scatter(tfs_embedded[:, 0], tfs_embedded[:, 1], marker='x', c=cluster_labels, cmap='hsv')
plt.title('t-SNE Visualization of K-Means Clustering (Questions Corpus)')
plt.show()

We can see some clusters are mostly on their own, while some are intermingled with other clusters. And the presence of the very prominent cluster as seen in the histogram below.
Distribution of cluster assignments
plt.hist(cluster_labels, bins=n_clusters)
plt.title('K-Means Cluster Assignment Distribution (Questions Corpus)')
plt.show()
Top 10 terms per cluster
Note that the words are the result of the preprocessing, tokenization, and removal of all stop words (and may be different that what they are in the raw text document).
# Get the tf-idf feature names.
tfidf_feature_names = sim.get_tfidf_feature_names()
# Sort the cluster centers into a descending list of the words that are most "relevant".
cluster_centers = cluster_centers.argsort()[:, ::-1]
# Create an array to render the top 10 words per cluster, using pandas DataFrame.
cluster_keywords = [tfidf_feature_names.take(cluster_centers[i, :10]) for i in range(n_clusters)]
df_cluster_keywords = pd.DataFrame(cluster_keywords)
df_cluster_keywords.columns = ['Word '+ str(i) for i in range(df_cluster_keywords.shape[1])]
df_cluster_keywords.index = ['Cluster '+ str(i) for i in range(df_cluster_keywords.shape[0])]
df_cluster_keywords
| Word 0 | Word 1 | Word 2 | Word 3 | Word 4 | Word 5 | Word 6 | Word 7 | Word 8 | Word 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Cluster 0 | resum | write | applic | resum resum | resum write | experi | employ | volunt | skill | write resum |
| Cluster 1 | class | high | cours | student | high class | class high | major | semest | studi | summer |
| Cluster 2 | teacher | teach | educ | teach teacher | elementari | teacher teach | teacher teacher | english | student | teacher educ |
| Cluster 3 | health | hospit | health care | hospit health | care | medic | doctor | healthcar | medicin | healthcar hospit |
| Cluster 4 | mechan | engin | mechan engin | engin mechan | engin engin | major mechan | major | field | degre | aerospac |
| Cluster 5 | comput | comput scienc | scienc | engin | comput engin | softwar | program | scienc comput | engin comput | comput softwar |
| Cluster 6 | life | write | balanc | journal | writer | life balanc | publish | english | student | social |
| Cluster 7 | studi | abroad | studi abroad | studi tip | tip | habit | studi studi | studi habit | way studi | way |
| Cluster 8 | nurs | nurs nurs | regist nurs | regist | practition | nurs practition | pediatr | pediatr nurs | neonat | healthcar |
| Cluster 9 | degre | student | graduat | high | money | univers | manag | way | social | start |
| Cluster 10 | engin | engin engin | civil | civil engin | softwar | aerospac | electr | chemic | softwar engin | chemic engin |
| Cluster 11 | medic | doctor | medicin | medic field | field | surgeon | med | doctor medicin | pediatrician | doctor doctor |
| Cluster 12 | account | account account | busi | account student | major account | major | student towson | towson | towson univers | univers account |
| Cluster 13 | lawyer | law | law lawyer | law law | lawyer law | lawyer lawyer | attorney | major | law practic | practic |
| Cluster 14 | psycholog | psychologist | major | clinic | major psycholog | clinic psycholog | counsel | psycholog major | degre | psycholog psycholog |
| Cluster 15 | scholarship | appli | appli scholarship | money | scholarship scholarship | financi | aid | financi aid | scholarship appli | scholarship financi |
| Cluster 16 | forens | forens scienc | scienc | forens scientist | scientist | forens forens | investig | scienc forens | crime | crimin |
| Cluster 17 | art | artist | culinari | culinari art | art art | fine art | fine | perform | love | major |
| Cluster 18 | major | minor | major major | choos | doubl | doubl major | choos major | major minor | undecid | chang |
| Cluster 19 | busi | busi busi | manag | start | busi manag | major | entrepreneurship | degre | start busi | busi major |
| Cluster 20 | sport | physic | physic therapist | therapist | therapi | physic therapi | athlet | sport manag | manag | major |
| Cluster 21 | loan | student loan | student | pay | debt | pay student | financi | money | loan loan | scholarship |
| Cluster 22 | polic | crimin | justic | crimin justic | offic | polic offic | law | enforc | law enforc | detect |
| Cluster 23 | design | graphic | graphic design | fashion | interior | fashion design | interior design | design graphic | art | design interior |
| Cluster 24 | technolog | inform | inform technolog | comput | tech | secur | softwar | engin | scienc | field |
| Cluster 25 | anim | veterinarian | veterinari | vet | veterinari medicin | medicin | anim anim | veterinarian veterinari | anim health | veterinari veterinari |
| Cluster 26 | financi | financ | invest | aid | financi aid | money | manag | invest manag | financi servic | financi plan |
| Cluster 27 | educ | higher | higher educ | stream | select | educ educ | teach | higher studi | degre | studi |
| Cluster 28 | music | music music | music industri | produc | music product | industri | musician | product | singer | music produc |
| Cluster 29 | game | video game | video | game design | design | game develop | game video | develop | game game | comput |
| Cluster 30 | internship | summer | internship internship | experi | appli | summer internship | student | intern | internship summer | appli internship |
| Cluster 31 | film | bengaluru | nagar | nagar bengaluru | act | bengaluru profession | gh nagar | gh | product | actor |
| Cluster 32 | biomed | biomed engin | engin | engin biomed | research | field | degre | biomed scienc | scienc | major |
| Cluster 33 | market | advertis | market advertis | busi | market market | media | major | social media | degre | manag |
| Cluster 34 | biolog | marin | marin biolog | biologist | major | scienc | major biolog | marin biologist | wildlif | research |
Similarity Approach - LDA
LDA or Latent Dirichlet Allocation, is an unsupervised generative model that assigns topic distributions to documents.
Topic models are based on the following basic assumption,
- Each document consists of a mixture of topics, and
- Each topic consists of a collection of words
The topics may not be known a priori, but the number of topics must be specified. Finally, there can be word overlap between topics, so several topics may share the same words.
After training, each document will have a discrete distribution over all topics, and each topic will have a discrete distribution over all words. However the model itself does not do any “classification”. But a logical approach would be to identify the dominant topics based on the topic that has the highest contribution for each document.
And in order to implement document similarity with this pipeline, we used the Euclidean Distance metric to find the top n documents that are closest, and therefore most similar.
Frequency Vectors - CountVectorizer
The first step is to convert the collection of raw text documents to a matrix of token counts. The following are some of the hyperparameters that we used,
max_df: 0.8. This is the maximum frequency within the documents a given feature can have to be used in the tf matrix. If the term is in greater than 80% of the questions or answers it probably has little meanining.
min_df: 2. Ignore terms that have a document frequency strictly lower than the given threshold. Setting this to a lower value resulted in a lot of overlapping words in the topics.
ngram_range: (1). This means we’ll only include unigrams.
preprocessor: We perform important text preprocessing like removing numbers and special characters, punctuations, coverting to lower case, and stripping any excess white space(s).
tokenizer: We use the NLTK’s PorterStemmer which reduces each word to its root using Porter’s stemming algorithm. We exclude our stop_words from the tokenization, because the stop_word removal occurs after the tokenization step.
stop_words: We create a custom stop_words list from the Tfidf English stop words, nltk English stop words, and corpus stop words! The last set of stop words were identified during the exploration phase that are very commonly present in a career-related text, and don’t convey much meaning during the learning. Some examples, school, college, career, jobs, years, advice, help etc.
Build the LDA Model
Now we are ready to build the LDA model using sklearn. Probably the most important hyperparameter for this step is to specify the number of topics/components. As we mentioned before, the topics may not be known a priori, but the number of topics must be specified. We decided to go with 30 topics for the questions corpus.
n_components: 30 Number of topics.
max_iter:10 The maximum number of iterations.
learning_method:’online’ In general, if the data size is large, the online update will be much faster than the batch update.
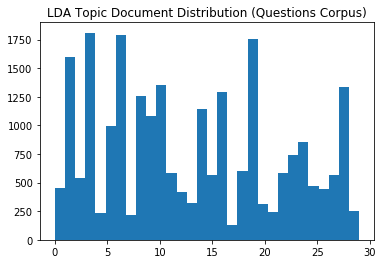
Topics Distribution across Documents (using Dominant topics)
As we mentioned, the model itself does not do any “classification”. But a logical approach would be to identify the dominant topics based on the topic that has the highest contribution for each document. Let’s use the infered dominant topics for each document to get an insight into the topic dictribution across all documents.
# Get the number of topics, and the dominant topics for each document (question).
n_topics, lda_dominant_topics = sim.get_lda_document_dominant_topics()
plt.hist(lda_dominant_topics, bins=n_topics)
plt.title('LDA Topic Document Distribution (Questions Corpus)')
plt.show()
Top 10 terms per Topic
Note that the words are the result of the preprocessing, tokenization, and removal of all stop words (and may be different that what they are in the raw text document).
# Get the LDA model, and related attributes.
lda, vectorized_question_corpus, vectorizer = sim.get_lda_visualization()
# Get the tf-matrix feature names.
feature_names = sim.get_tf_feature_names()
# Grab the top 10 words per topic, from the lda model components_ attribute.
topic_keywords = []
for topic_weights in lda.components_:
topic_keywords.append(feature_names.take(topic_weights.argsort()[::-1][:10]))
# Render the top 10 words per topic, using pandas DataFrame.
df_topic_keywords = pd.DataFrame(topic_keywords)
df_topic_keywords.columns = ['Word '+str(i) for i in range(df_topic_keywords.shape[1])]
df_topic_keywords.index = ['Topic '+str(i) for i in range(df_topic_keywords.shape[0])]
df_topic_keywords
| Word 0 | Word 1 | Word 2 | Word 3 | Word 4 | Word 5 | Word 6 | Word 7 | Word 8 | Word 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Topic 0 | pursu | pre | med | undergradu | veterinari | veterinarian | medicin | occup | vet | basic |
| Topic 1 | comput | game | scienc | learn | technolog | program | develop | skill | softwar | languag |
| Topic 2 | design | account | industri | graphic | administr | interior | tell | aviat | airlin | student |
| Topic 3 | degre | art | long | master | graduat | bachelor | field | pursu | forens | plan |
| Topic 4 | type | anim | volunt | select | allow | posit | model | local | caus | background |
| Topic 5 | student | pay | social | futur | money | loan | famili | freshman | media | thing |
| Topic 6 | univers | high | colleg | commun | student | program | attend | state | decid | senior |
| Topic 7 | experi | area | gain | wonder | edit | face | let | knowledg | publish | hous |
| Topic 8 | medic | doctor | medicin | field | healthcar | hard | surgeon | physician | exactli | easi |
| Topic 9 | nurs | film | act | invest | assist | regist | pediatr | undecid | potenti | practition |
| Topic 10 | educ | wonder | teacher | teach | physic | cours | high | therapi | therapist | student |
| Topic 11 | write | financ | financi | person | import | employ | chanc | stay | home | great |
| Topic 12 | money | idea | goal | train | polit | creativ | way | achiev | challeng | focu |
| Topic 13 | start | compani | prepar | process | expect | gener | new | hire | entrepreneurship | especi |
| Topic 14 | major | scienc | biolog | math | chemistri | women | doubl | fit | path | option |
| Topic 15 | scholarship | appli | aid | way | pharmaci | websit | tuition | event | paid | incom |
| Topic 16 | engin | mechan | environment | civil | field | chemic | reason | softwar | car | industri |
| Topic 17 | histori | conserv | risk | fast | midwif | rememb | listen | action | sit | museum |
| Topic 18 | class | internship | high | junior | public | pediatrician | place | econom | requir | govern |
| Topic 19 | busi | path | market | counsel | field | choic | consid | higher | thank | right |
| Topic 20 | research | profession | organ | hour | mathemat | aspir | non | outsid | guid | aspect |
| Topic 21 | kind | play | marin | read | old | fun | pro | biolog | quit | player |
| Topic 22 | music | order | english | love | danc | perform | product | curiou | theatr | countri |
| Topic 23 | life | manag | grade | enjoy | understand | stress | worri | balanc | averag | tech |
| Topic 24 | sport | choos | interview | fashion | difficult | human | level | athlet | resourc | secur |
| Topic 25 | applic | resum | appli | admiss | servic | step | activ | join | club | stand |
| Topic 26 | health | hospit | care | relat | travel | complet | salari | aerospac | clinic | electr |
| Topic 27 | graduat | success | professor | offic | crimin | polic | justic | benefit | kid | neurosci |
| Topic 28 | studi | psycholog | law | lawyer | tip | intern | abroad | test | subject | special |
| Topic 29 | minor | dream | stem | passion | heard | competit | advanc | pick | chef | wish |
Topics-Keywords Distribution Visualization using pyLDAvis
The pyLDAvis library offers the best visualization to view the topics-keywords distribution.
A good topic model should have non-overlapping, fairly big sized blobs for each topic.
pyLDAvis.enable_notebook()
panel = pyLDAvis.sklearn.prepare(lda, vectorized_question_corpus, vectorizer, mds='tsne')
# Save the pnael to html for rendering in notebook
pyLDAvis.save_html(panel,'./lda_vis.html')
# Render the panel.
# pyLDAvis.display(panel)
HTML(filename='./lda_vis.html')
Comparison of the Similarity Approaches
LSA Pipeline
Some of the challenges with this pipeline were determining the optimum number of dimensions for SVD, and the need for a really large set of documents and vocabulary to get accurate results.
With the K-Means Clustering, we tried the Elbow Method to find the optimal number of clusters, with no clear indication. The distribution of cluster assignments was not very uniform, and perhaps can be attributed to the ineffectiveness of clustering very short text documents.
In general, LSA was quick and efficient to use, and performed fairly well.
LDA Pipeline
LDA seemed very promising (Topics-Keywords Distribution, Topics-Documents Distribution) but during our run and read evaluation, we did not observe good results. We then realized that LDA probably does not work well with very short documents, and a lot of the questions have fewer that 50 words. Very briefly, this is because the model infers parameters from observations and if there are not enough observations (words) in a document, the model performs poorly. Unfortunately, we were unable to run the entire answers corpus on the LDA Pipeline, due to insuffiecient computational resources.
Additionally there are a few other distance metrics like the Jensen-Shannon Distance, and Hellinger distance that may be better suited to quantify the similarity between two probability distributions, and could be explored further.
Recommendation Approach
Given the scope and timeline of this project, we developed two major components of our recommendation system. The first piece delivers question-answer pairs that are most similar to a given new question and was developed with the goal of alleviating demand for non-unique questions by showing students similar questions that may already have a satisfactory answer. The second piece assigns new questions to professionals that have answered similar questions before.
We fit the text data to our recommendation system.
We’ve developed a recommender.py module to handle the top level processes for making recommendations on both the question asker and question answerer sides. We’ve developed a similarity.py module to handle computing similarity metrics for our text data.
We pass in the question corpuses into our similarity.py module and compute a similarity matrix of questions against themselves and all other questions in the data set. We use this similarity matrix to compute against new questions as they come into the system to find similar questions and the professionals who have answered them.
rec = recommender.Recommender()
rec = rec.fit(data)
For every new question, we recommend similar question-answer pairs to the question asker and the new question to those pairs’ answerers’.
We do this by computing a similarity vector for the new question and sorting it in descending order. We then select the first k similar questions based on their similarity scores and use pandas merging functions to get their associated answers and answerers.
Evaluation
We’ve developed a evaluator.py module to handle evaluating a recommendation approach on a particular similarity metric using two evaluation metrics: Mean Average Precision at K (MAP@K) and personalizaiton.
eval = evaluator.Evaluator(rec)
MAP@K is an evaluation metric that looks at a set of recommendations for a user and determines the average precision of that set. The benefit of using average precision as opposed to overall precision is so we can reward a system for front-loading relevant recommendations. For example, a set of [1, 0, 0] will have a higher average precision than a set of [0, 1, 0] because the relevant recommendation was in the first position.
As this challenge is an unsupervised problem, we needed to transform it into a semi-supervised problem by defining our own labels on what is “relevant” to a user. To that end, we evaluated three different definitions of “relevant”. Due to computation restrictions, we were only able to evaluate MAP@3. However, we believe a recommendation set of 3 is a decent approximation of what a true recommendation set would look like to a user with limited time and attention. Additionally, we limited our average precision computations to users that had at least 4 (k+1) and less than 10 answers in their answer history, once again due to computation restrictions. Ideally, we would want to run this evaluation for all users, especially since CareerVillage has a few power users that have answered hundreds of questions.
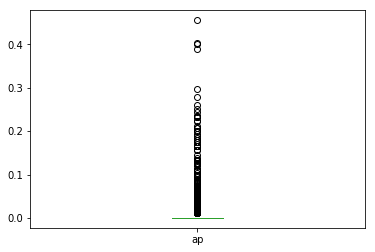
MAP@K for Exact Match
First, we evaluated MAP@3 for questions that were exact matches in a users answer history. We compared each recommended question id to a list of question ids in a user’s answer history and only assigned a “relevant” binary flag of 1 if the recommended question id was an exact match. Below is a boxplot of the distribution of average precision at 3 for each user in our dataset using this exact match approach. Our MAP@3 for the exact match approach is unfortunately atrociously low at about 1.2%.
print(eval._get_map('exact'))
eval.map_at_k['exact'].plot(kind='box')
0.012193688769828452
<matplotlib.axes._subplots.AxesSubplot at 0x32da40dd8>
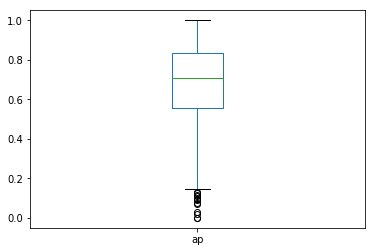
MAP@K for K-Means LSA Clusters
Second, we evaluated MAP@3 for questions that belonged to the same K-Means cluster. We compared the K-Means cluster label of each recommended question to a list of K-Means cluster labels for all questions in a user’s answer history and assigned a “relevant” binary flag of 1 if the recommended cluster label was in the list. Below is a boxplot of the distribution of average precision at 3 for each user in our dataset using the K-Means LSA clustering approach. Our MAP@3 for this clustring approach is much better than in the exact match scenario, clocking in at 66%.
print(eval._get_map('lsa'))
eval.map_at_k['lsa'].plot(kind='box')
0.6902299226620279
<matplotlib.axes._subplots.AxesSubplot at 0x12eb2cda0>
MAP@K for LDA Dominant Topic Clusters
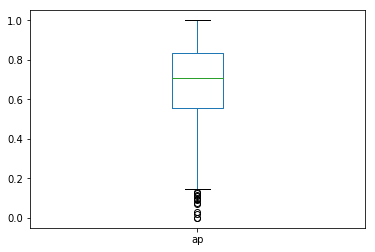
Lastly, we evaluated MAP@3 for questions that had the same dominant LDA topic. We compared the dominant LDA topic of each recommended question to a list of dominant LDA topics for all questions in a user’s answer history and assigned a “relevant” binary flag of 1 if the recommended dominant topic was in the list. Below is a boxplot of the distribution of average precision at 3 for each user in our dataset using the domnant topic clustering approach. Our MAP@3 for this clustering approach actually yields the same precision as in the LSA clustering approach. This may indicate the dominant topic and the K-Means cluster keywords may be aligning in some way.
print(eval._get_map('lda'))
eval.map_at_k['lda'].plot(kind='box')
0.6902299226620279
<matplotlib.axes._subplots.AxesSubplot at 0x12e4b7828>
Personalization
Personalization is an evaluation metric that looks at all users’ recommendation histories and computes similarity across what has been recommended to each user. The higher a personalization score, the more unique tailored recommendations are to each user.
We computed the overall personalization for our entire set of users and observed a score of approximately 0.3. This means that each users recommendations are about 70% similar to all other users recommendations. This is by no means a fantastic personalization score, however, we suspect the presence of a large cluster of general college and career questions may dilute the individual customization of each users recommendation set.
eval.personalization
0.30015197568388974
Lessons Learned
- If you can implement it in base Python, implement it in numpy.
- Indexing matrices is much faster than re-computing vectors in an elementwise fashion.
- Focus on one aspect of a system and develop it out before trying to tackle another.
Areas of Further Interest
This project really tested our computer’s processing power and our personal standards for acceptable run times. There are a whole slew of ideas that we wanted to build into our recommendation system that we simply couldn’t reasonably implement and test. We’ve listed them here below to let it be known that, yes, indeed, we did consider the following:
- Computing similarity vectors between professionals’ features to incorporate brand new members of CareerVillage who don’t have an answer history yet
- Computing similarity vectors on the answer corpus to supplement our similar question recommendation approach
- Computing similarity vectors between professionals’ features and students’ features to enhance new question recommendations
- Operationalizing answering behavior of professionals to classify them by ‘active’ and ‘inactive’ and scheduling email chains accordingly to minimize churn
Example Recommendation
The below cell can be run to simulate a recommendation by pulling a random question from the data and running it through the recommendation system.
rec.demonstrate_recommendations()
Recommendations based on Cosine Similarity
New question: How many clubs, internships, and work study programs is too much? I am attending the University of Washington this upcoming fall and will be majoring in biochemistry. My goal is to get accepted into med school in the future which obviously requires many extracurricular activities and volunteer work. Currently, I am signed up for work study, I plan to get involved with at least 2 science-based clubs (maybe even become coordinator or president of those clubs), and do volunteer work on the side at the local hospital. Is jumping in head-first the right thing to do? Should I ease back on everything? If so, will my med school application be less desirable if so have less going on during my undergraduate? Thank you to whoever can help me! #internships #medical-school #undergraduate #college-applications #extracurriculars
Similar Question 1: How important are extracurricular activities? I'm an active member of several clubs, but I'm not a leader or president or anything. I want to build my resume, but I'm not exactly sure what stands out. The clubs I'm apart of are: Model UN, Forensics, FBLA and Science Club. (And I'm not participating to get into college, I'm doing them because they're fun.) #clubs #activities #resume
Similar Answer 1: Rebekah,When you don't have much work history to put on a resume, you can put some extra-curriculars on it. Be careful not to list so much that it appears you could possibly have scheduling conflicts that would preclude you from working! Even though you are not in a leadership role, you want to look towards activities you participated in. Did you plan a car-wash? Have you worked the soda counter at the game? Try to find things that show how you have experience handling money, doing customer service, following rules, being dependable, etc. These are transferable skills that will help you land a job. (If possible, try in the future to take a more active role in leadership).On the resume, explain VERY briefly what the club is, what it does. Not everyone knows about Model UN, FBLA, etc.As you gain work experience, you will drop off school activities, usually. But, you can acquire other activities, as an adult. Some employers like to see community involvement, and expect you to participate when they are out doing charitable events in their company t-shirts! It could be that "little extra" that results in you getting hired!Good luck!Kim
Answer 1 Author: be5d23056fcb4f1287c823beec5291e1
Similar Question 2: What extracurricular activities are the most impressive and unique for applying to medical school? Most students will become CNAs or volunteer at local hospitals, but what extracurricular activities will stand out on med school applications? #applications #med-school #medical-school #graduate-school #college
Similar Answer 2: Paige,Scribe! Although this may sound like a "typical activity," this is one of the top clinical experience a pre-medical student can choose. Not only to you work directly with physicians, but you go into every room, and witness the physician-teaching style that may inspire you to be a physician. This is your chance to show medical schools that you understand the rigors of what it takes to be a physician and why it inspires you to continue on this path. Yes, the above mentioned are great ways to get your feet wet in a clinical setting, but from my experience, scribing puts you in direct contact with physicians, and thus they can become your mentor and write you your letters of recommendation.
Answer 2 Author: 83276d7bfcc342eb9d7ada3033bf4169
Similar Question 3: How can I get more involved in college? I had 3 extracurricular clubs in high school and I'd like to be more active in volunteering while I am at college. #activist
Similar Answer 3: Hi Brittany,Getting involved in college through a club, organization, volunteering, etc. is a great way to engage your community. I suggest keeping your eye out on emails from your school, as many times they include information on clubs/orgs etc., in addition, at the beginning of the year many universities hosts events with clubs/orgs to engage students. Some offices or departments offer ambassador or educator roles for students to become peer advisors, which may be of interest.At IUPUI we have social justice educators, alternative break leaders, political engagement scholars, etc. I would say you're doing an excellent job managing expectations. I always feel it's better to be deeply engaged in 2-3 activities than try to do ALL the things.
Answer 3 Author: 09b4760d2e3c493fb2515b8a83130902
Recommendations based on LDA
New question: How many clubs, internships, and work study programs is too much? I am attending the University of Washington this upcoming fall and will be majoring in biochemistry. My goal is to get accepted into med school in the future which obviously requires many extracurricular activities and volunteer work. Currently, I am signed up for work study, I plan to get involved with at least 2 science-based clubs (maybe even become coordinator or president of those clubs), and do volunteer work on the side at the local hospital. Is jumping in head-first the right thing to do? Should I ease back on everything? If so, will my med school application be less desirable if so have less going on during my undergraduate? Thank you to whoever can help me! #internships #medical-school #undergraduate #college-applications #extracurriculars
Similar Question 1: What are my chances of getting into an ivy league school? I'm a junior in high school. I have a pretty decent GPA and I have all A's. I've done a tone of program like internships abroad at hospitals and labs and I'm currently doing a leadership program with Princeton and a mentor-ship program with a pharmaceutical company called Novartis. I'm in 5 clubs and I hold leadership positions in 3 and will be holding leadership in all 5 next year. I currently take 3 AP classes and I probably will take 5 next year. I still haven't taken my SATs but my PSAT score was a 1440. I want to major in bioengineering or biomedical engineering. So does anyone know my chances? #college #college-admissions #college-selection #ivy-league
Similar Answer 1: 1, IVY requirement for students, not just how much scores but from "applying for the students' comprehensive quality, for the students' qualities, belong to our objects, to be accepted by the applicant can bring me first how fresh air, the applicant may make how dedication" to the society after graduation to consider many aspects, such as; 2. Generally speaking, the admission requirements are divided into two parts: 1) first, measurable achievements, such as high school grades, toefl, SAT scores, etc. High school grades are at least GPA3.5 (about 85 points). High school graduation, toefl should be more than 100 points, over SAT2200. IVY's acceptance rate hovers around 10%, and if you have the above, you can really enter the competition. 2) the other part of the admissions requirement is the "soft condition". The most important question is to let the school know exactly how the applicant is different from other people. What's more, if they are accepted by these elite universities, they will contribute to these schools or society after graduation. There are some "soft conditions" that can be used in unusual talent, such as drawing, playing piano, etc., for example: zhou X (toefl 102, SAT2240,GPA 3.7), in the application, the use of the form of cartoon to tell the life of the day, left a deep impression to AO's teachers, and smoothly accepted by IVY." Talent "can't just be, but must be refined -- because from the depth of talent, you can see the students' perseverance and enthusiasm for life, which is what the school is looking for. Can also is through social activities, club activities is an applicant can show leadership potential, also can be reflected and want to contribute to the understanding of the human suffering volunteer activities, such as have a yellow Y classmates, in addition to maintain excellent academic performance, and the rich social practice experience, resume internship experience alone wrote 2 pages of A4 paper, she is very good use of these experiences and gain enlightenment and implications for school presents a rich applicants, such applicant granted is appreciated by IVY. 3. For students who are already in high school in the United States, the advantages are much higher than those in high school in China. If possible, in high School to go to the right School Summer School also is very good opportunity, into the Summer School study, not only can learn more about the School, it is also possible to make schools more in-depth understanding of the applicant.
Answer 1 Author: 790457bbdd524bc580d2e96fff04c646
Similar Question 2: What is the academic environment at the University of Michigan and is it possible to balance a rigorous course load with Marching Band? To current students, alumni, and professionals at the University of Michigan Ann Arbor, what is the teaching style at U of Mich and how rigorous is the biology major course load? Would it be possible to succeed in those courses while simultaneously participating in the U of Mich Marching Band, should I wish to continue color guard? #biologymajor #biology # universityofmichigan #colorguard #flaglifechoseme
Similar Answer 2: Hi Kateryna -- I am neither a UM alum, nor a bio major, nor did I march at a Div 1 school, but I'm the parent of a son who marched at Pitt for 4 years while studying engineering. And I don't know a lot about the flag section.So here's what I know. UM is rigorous. It has an excellent academic reputation and please expect that you will have as difficult a course load as you wish. Marching in a Div 1 band is almost like a full-time job. I see that you are interested in flags, I don't know how much that will be different from what the instrumentalists schedule is -- the instrumentalists have daily rehearsals. The UM Flag site says there are 32 members with 24 block spots. So it's really important to them to have all 24 spots filled on the field -- so even if you make the squad, you'll be competing to be one of the 24 on game day.On home game days, your entire day will be taken up with pre-game, game and post-game activities with the band. So your fall semesters will be very busy. But it's possible. After all, if it weren't, there wouldn't be anyone marching flags, would there? So go ahead and tryout for flags, and take that first step. The director and section leader is there to help, and it's a great way to make new friends. Best of luck! Lisa
Answer 2 Author: a3e10d5011324d11be25e4ce1547be0b
Similar Question 3: What activities should I be participating in in high school to be able to apply for an undergraduate degree used to get into medical school? I want to be a neurosurgeon and am overwhelmed with the amount of colleges I could apply to for undergrad. I am currently leading two different sections of the robotics team at my school and am thinking about taking summer classes to become an EMT to get hands on-experience in the medical field. #physician #surgeon #undergraduate #medical-student #college-selection #college #college-admissions #academic-advising
Similar Answer 3: I would like to start by saying that you are already crushing it and should be very proud! I know how hard it is to sift through all of the information about colleges and it is easy to feel like you are never doing enough. I think it's extremely important to do the things outside of the classroom that bring you the most joy, but also challenge you intellectually. Doing so will allow you to gain insight into what you may want to do professionally. Working as an EMT is a great way to learn more. You can also reach out to local hospitals about volunteering or shadowing doctors. Shadowing professionals in the field you're most interested in is a great way to learn and expand your network. Choosing a college should be a comprehensive decision based on more than the accolades the school has received. Visit schools you may be interested in and try to get to know some students there and sit in on a class. If you can envision yourself there, it's the place for you! YOU GOT THIS! Best of luck!
Answer 3 Author: dd8c2039c2fd46a18404770a4e47cb12
Recommendations based on KNN
New question: How many clubs, internships, and work study programs is too much? I am attending the University of Washington this upcoming fall and will be majoring in biochemistry. My goal is to get accepted into med school in the future which obviously requires many extracurricular activities and volunteer work. Currently, I am signed up for work study, I plan to get involved with at least 2 science-based clubs (maybe even become coordinator or president of those clubs), and do volunteer work on the side at the local hospital. Is jumping in head-first the right thing to do? Should I ease back on everything? If so, will my med school application be less desirable if so have less going on during my undergraduate? Thank you to whoever can help me! #internships #medical-school #undergraduate #college-applications #extracurriculars
Similar Question 1: How important are extracurricular activities? I'm an active member of several clubs, but I'm not a leader or president or anything. I want to build my resume, but I'm not exactly sure what stands out. The clubs I'm apart of are: Model UN, Forensics, FBLA and Science Club. (And I'm not participating to get into college, I'm doing them because they're fun.) #clubs #activities #resume
Similar Answer 1: Rebekah,When you don't have much work history to put on a resume, you can put some extra-curriculars on it. Be careful not to list so much that it appears you could possibly have scheduling conflicts that would preclude you from working! Even though you are not in a leadership role, you want to look towards activities you participated in. Did you plan a car-wash? Have you worked the soda counter at the game? Try to find things that show how you have experience handling money, doing customer service, following rules, being dependable, etc. These are transferable skills that will help you land a job. (If possible, try in the future to take a more active role in leadership).On the resume, explain VERY briefly what the club is, what it does. Not everyone knows about Model UN, FBLA, etc.As you gain work experience, you will drop off school activities, usually. But, you can acquire other activities, as an adult. Some employers like to see community involvement, and expect you to participate when they are out doing charitable events in their company t-shirts! It could be that "little extra" that results in you getting hired!Good luck!Kim
Answer 1 Author: be5d23056fcb4f1287c823beec5291e1
Similar Question 2: What extracurricular activities are the most impressive and unique for applying to medical school? Most students will become CNAs or volunteer at local hospitals, but what extracurricular activities will stand out on med school applications? #applications #med-school #medical-school #graduate-school #college
Similar Answer 2: Paige,Scribe! Although this may sound like a "typical activity," this is one of the top clinical experience a pre-medical student can choose. Not only to you work directly with physicians, but you go into every room, and witness the physician-teaching style that may inspire you to be a physician. This is your chance to show medical schools that you understand the rigors of what it takes to be a physician and why it inspires you to continue on this path. Yes, the above mentioned are great ways to get your feet wet in a clinical setting, but from my experience, scribing puts you in direct contact with physicians, and thus they can become your mentor and write you your letters of recommendation.
Answer 2 Author: 83276d7bfcc342eb9d7ada3033bf4169
Similar Question 3: How can I get more involved in college? I had 3 extracurricular clubs in high school and I'd like to be more active in volunteering while I am at college. #activist
Similar Answer 3: Hi Brittany,Getting involved in college through a club, organization, volunteering, etc. is a great way to engage your community. I suggest keeping your eye out on emails from your school, as many times they include information on clubs/orgs etc., in addition, at the beginning of the year many universities hosts events with clubs/orgs to engage students. Some offices or departments offer ambassador or educator roles for students to become peer advisors, which may be of interest.At IUPUI we have social justice educators, alternative break leaders, political engagement scholars, etc. I would say you're doing an excellent job managing expectations. I always feel it's better to be deeply engaged in 2-3 activities than try to do ALL the things.
Answer 3 Author: 09b4760d2e3c493fb2515b8a83130902